
Tự học Machine Learning (Phần 1)
Lâu lắm mình mới viết blog lại nên đoạn đầu sẽ lan man 1 tí, các bạn có thể skip và đi vào nội dung chính ở bên dưới nhé.
Tính tới hôm nay là mình chính thức đi làm software engineer được khoảng 7 năm. Trong 7 năm này, mình đã làm qua 4 công ty product về những lĩnh vực không liên quan gì nhau: OTT app (Zalo), e-commerce (Tiki), crypto trading (Quoine/Liquid) và AI (VinAI). Lí do mà mình chuyển qua những product khác mà có domain không liên quan gì ở công ty cũ 1 phần là vì đú trend. Có thể 1 số mảng trên bị overhyped nhưng lúc mình vào những team đấy thì product đó đều đang là xu hướng của thế giới. Phần còn lại là mình muốn học thêm những kiến thức mới bên cạnh kiến thức về software/programming.
Khá may mắn là tính mình rất tò mò nên có thời gian là mình sẽ tìm hiểu thêm về những kiến thức của product mình làm. Đương nhiên cách mình tìm hiểu không phải để trờ thành chuyên gia về lĩnh vực đó (mình vẫn thích programming hơn), chỉ muỗn học thêm để thỏa mãn những câu hỏi trong đầu mình. Ở Zalo, mình học được cách âm thanh được xử lý và lưu trữ, sau đó gởi qua internet như thế nào, 1 product mobile first (only) được build ra sao. Tiki dạy mình cách 1 e-commerce hoạt động, marketing làm sao, và 1 startup được build từ con số 0 sẽ như thế nào. Ở Quoine thì mình có tìm hiểu về lịch sử tiền tệ, cách blockchain hoạt động, tại sao nó sẽ là xu hướng, cách mã hóa của những crypto currency ra sao (mấy cái này có blog của anh Dương Ngọc Thái viết khá hay). Và hiện tại ở VinAI, mình cũng đang bỏ thời gian cuối tuần ra để học thêm về AI (chủ yếu là Machine Learning). Bắt đầu nội dung chính từ dòng dưới nhé
2 tháng qua mình có đang học về ML từ 2 nguồn: Sách Machine Learning cơ bản của thầy Tiệp (50%) và lớp Machine Learning của Andrew Ng trên Coursera (20%). Với những ngày đầu học thì mình có hơi cảm giác chán, vì nó hỏi basic chứ không đi vào thẳng để giải quyết những vấn đề khi mình gặp ở trên công ty. Nhưng khi tìm hiểu được 1 thời gian thì mình cảm giác ML khá là hay và gần gũi. Lúc chưa bắt đầu mình luôn nghĩ AI/ML là 1 thứ gì đó rất cao siêu mà chỉ dành cho các master, phD nghiên cứu. Nhưng thật ra phần basic của ML khá gần với toán cấp 3, và những vấn đề ML giải quyết nhìn chung cũng khá giống với suy nghĩ con người (chứ không máy móc gì lắm :v). Đối với mình phần basic như vậy là quá đủ để thỏa mãn và dễ hiểu, còn những thứ cao siêu hơn thì chắc giành cho những bạn nghiên cứu sinh, master, phD. Nên hôm nay mình quyết định blog lại những thứ mình tìm hiểu được dưới "góc nhìn" của 1 người chưa từng biết gì về ML, và sẽ không hề có programming ở đây luôn, chỉ cần toán cấp 3 là hiểu (thật ra mình cũng phải ngồi học lại toán cấp 3 khá nhiều để hiểu :v).
Blog này chỉ để tóm tắt lại những cái mình đã học được các bạn đọc xong thấy có hứng thú tìm hiểu sâu hơn thì nên học từ 2 nguồn trên nhé.
Marchine Learning là gì?
Vậy machine learning là gì? Theo mình machine learning là dạy máy tính giải quyết 1 "vấn đề" nào đó bằng 1 lượng "thông tin có sẵn", sau đó với lượng "thông tin mới" đưa vào, máy tinh sẽ trả về "kết quả" gần với kết quả tốt nhất.
Giống như khi bạn dạy 1 đứa trẻ đọc chữ. Việc đầu tiên bạn phải viết chứ đấy ra, sau đó chỉ cho đứa trẻ đó biết là chữ nào với hình dạng đó sẽ là chữ "A". Sau khi học được kiến thức đó thì đứa trẻ sẽ nhận biết được chữ "A" ở bất kì đâu chứ không riêng gì mỗi chữ của bạn viết ra lúc dạy. Vậy "vấn đề" ở đây là đứa trẻ nhận biết được chữ "A", "thông tin có sẵn" là chữ bạn viết ra và bạn nói đó là chữ "A", "thông tin mới" là những chữ viết ở chỗ khác, và "kết quả" là đứa trẻ sẽ biết đó là chữ "A". Như vậy để xây dựng được 1 ML model, cần phải đi qua 4 bước sau:
- Xác định vấn đề.
- Biểu diễn vấn đề: Đối với con người, bạn có thể biểu diễn bằng lời nói, bằng hình ảnh hoặc cử chỉ. Nhưng với máy, bạn phải biểu diễn nó qua dạng số, ở đây là toán học.
- Xây dựng hàm mất mát.
- Dạy máy học bằng data (thông tin có sẵn).
Xác định vấn đề
- Đầu tiên, để xây dựng được 1 thuật toán ML, chúng ta cần phải biết được đề bài ở đây là gì. Khác với con người, Những vấn đề của ML basic mà mình đang học thì cần phải specific hơn 1 tí, tạm phân lọai vấn đề thành 3 lọai theo mình là phổ biến sau:
- Classification: Đây là chó hay mèo? Con số đang viết trên giấy là số mấy? Người đối diện là nam hay nữ???
- Regression: Định giá 1 căn nhà, đoán tuổi của 1 người.
- Clustering: Phân loại gu âm nhạc của mọi người. Phân nhóm học sinh theo thế mạnh (chuyên toán, chuyên tin,….).
Biểu diễn vấn đề
- Như mình đã nói ở trên thì cách giải 1 vấn đề của ML sẽ cần tới kiến thức toán học. Mọi vẫn đề sẽ được biểu diễn lại bằng phương trình toán học. Ví dụ với bài toán đơn giản sau:
- Nếu mình vào quán uống 1 ly cafe với giá 3usd, thì gọi x là số ly cafe ta uống, y là số tiền cần phải bỏ ra, ta có:
- y = 3x
- Nhưng nếu trong 3usd đó có 1usd là phí chỗ ngồi. Vậy giá cho 1 ly cafe chỉ là 2usd. 2 ly cafe, giá chỉ là 4usd. Tương tự 3 ly là 6usd. Ta có phương trình:
- y = 2x + 1
- Lại phức tạp vấn đề lên 1 tí, chúng ta đã bỏ qua 1 yếu tố là mình có ngồi đó suốt ngày để uống cafe hay không. Hay là sáng uống 1 ly, xong ra về đi ăn trưa. Rồi chiều quay lại uống 1 ly nữa. Lúc này giá tiền phải là 6usd cho 2 ly cafe. Phương trình lúc này sẽ có dạng:
- y = 2x1 + x2 (x1 là số ly cafe, x2 là số lần ra vào quán)
- Sau khi có phương trình này rồi, viêc của bạn chỉ cần nhập số ly cafe uống và số lần ra vào quán thì sẽ nhận được số tiền bạn phải bỏ ra.
- Nếu mình vào quán uống 1 ly cafe với giá 3usd, thì gọi x là số ly cafe ta uống, y là số tiền cần phải bỏ ra, ta có:
- Tổng quát lại thì ra sẽ có phương trình y = a * x1 + b * x2. Với những bài toán khác nhau, ta sẽ có phương trình khác nhau. Ví dụ, với định giá nhà thì ta có thể có nhiều yếu tố ảnh hưởng kết quả hơn (chiều rộng, mặt tiền, khoảng cách tới trung tâm,…) thì lúc này phương trình sẽ phức tạp hơn. Nhưng nhìn chung, bạn sẽ cần 1 phương trình với vector x (vì sẽ có nhiều yếu tố nên x sẽ là 1 vector) là các yếu tố đầu vào, và y là kết quả bạn cần muốn biết. Bên cạnh đó, các giá trị a, b sẽ được kí hiệu là 1 vetor w. Như vậy, công thức tổng quát sẽ là:
- y = w0 * x0 + w1 * x1 + ….. + wn * xn
- Tất nhiên là sẽ có rất nhiều phương trình phức tạp hơn rất nhiều. Có 1 số cách biểu diễn mình đã được học ở cấp 3 hoặc đại học, chỉ là lúc đấy mình chưa biết phải làm gì với nó. Nếu có thời gian, mình sẽ viết tiếp 1 số bài mà mình thấy hay ở những blog sau.
- Sau khi biểu diễn được vấn đề theo ngôn ngữ toán học. Bước tiếp theo, chúng ta cần xác định cần phải làm gì với phương trình này. Với mong muốn cuối cùng là khi cho dữ liệu đầu vào, máy sẽ trả về kết quả cho mình, nghĩa là chúng ta sẽ nhập vector x vào phương trình và nhận về kết quả y. Nên việc tiếp theo chúng ta cần phải đi tìm những giá trị w của phương trình.
- Ở ví dụ trên, mình đã tìm các số w bằng cách sử dụng dữ liệu đầu vào, ở đây ra các giá trị x và y.
- Với x1 = 1, x2 = 0, y = 3 -> mình tìm được w0 = 3, w1 = 0
- với x1 = 1, x2 = 1, y = 3 -> mình tìm được w0 = 2, w1 = 1
- Đến đây, các bạn có thể hiểu là chúng ta sẽ dùng những data đã được gán nhãn sẵn (với 1 vector x, sẽ có 1 giá trị y tương ứng) như chữ “A” viết trên giấy được gắn nhãn là “A”, để tìm ra các giá trị w. ML có 1 khái niệm là hàm mất mát (loss function) để thực hiện tìm ra các giá trị w này.
Hàm mất mát
- Giả sử ta có hàm y = w0 * x0 + w1 * x1 viết gọn lại là y = w * x (với x và w là 2 vector). Trong trường hợp hoàn hảo như bài toán mua cafe ở trên thì chúng ta tìm được w = [2, 1] thỏa mãn phương trình trên cho mọi điểm data. Tức là mọi điểm trong tập data đều nằm trên đường thằng của đồ thị y = w * x. Nhưng với 1 tập data khác, ví dụ tính giá nhà dựa vào diện tích căn nhà, với loại data này thì 1 m2 nhà đất tuy cùng 1 khu vực nhưng có thể chênh lệch nhau chút ít. Vì vậy tìm ra vector w để thỏa mãn y = w * x (với mọi x, y trong tập data) là bất khả thi. Vậy chúng ta sẽ gọi y’ = w * x thay vì y.
- Với y và y’, chúng ta cần tìm w sao cho y - y’ càng nhỏ càng tốt, về 0 là trường hợp lí tưởng bên trên. Vì vậy ML sinh ra 1 khái niệm tên là hàm mất mát. Với tất cả các data (x và y) cho trước, chúng ta cần tìm w sao cho tổng các giá trị y - y’ là nhỏ nhất. Cũng có thể hiểu tổng khoảng cách từ các điểm data tới đường thẳng y = w * x là nhỏ nhất (như hình). Vậy tên hàm mất mát có ý nghĩa là chúng ta sẽ tìm w sao cho tổng các mất mát (y - y’) là nhỏ nhất. Với y’ là kết quả được tính = w * x, còn y là của tập data ban đầu.
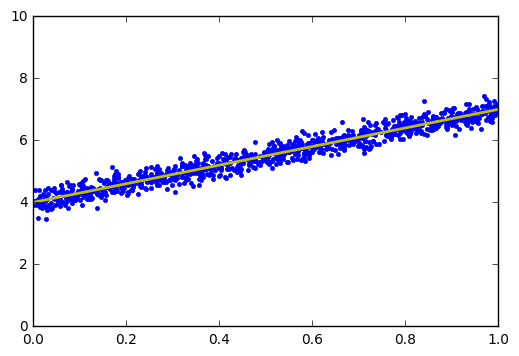
Dạy máy học
- Sau khi đã biểu diễn được vấn đề qua dạng toán học, cũng như tìm được công thức tổng quát của hàm mất mát. Viêc cần làm tiếp theo là chúng ta cho data được đánh nhãn sẳn (giá nhà 3m2 là 5tr, 6m2 là 9tr,…) vào hàm mất mát để tính ra giá trị tối ưu nhất của w.
- Để tìm w sao cho hàm mất mát ra giá trị nhỏ nhất. Thì có rất nhiều cách. Đa số các cách đều dùng đạo hàm đề xác định điểm cực tiểu của hàm số (min), cho tới thời điểm mình đọc tới đoạn này mình mới biết ứng dụng của đạo hàm để làm gì, cảm thấy những năm học toán ở cấp 3 đến bây giờ mới có thể lấy ra dùng. Mình sẽ viết chi tiết cách tối ưu hàm mất mát này ở những bài sau.
- Sau khi tìm được vector w, thì chúng ta đã có được 1 model ML, sau đó chỉ cần nhập số m2 nhà của bạn (x) thì bạn sẽ nhận được kết quả y của model tính toán được.
Với mình đây là 1 quy trình basic và dễ hiểu nhất để làm ra 1 model ML và cách ML giải quyết vấn đề nào đó. Còn rất nhiều kiến thức khác, rất nhiều lời giải cũng như nghiên cứu trên thế giới. Mình sẽ tìm hiểu và blog lại nếu có thời gian.